Appearance
传统测试用例设计
1.软件产品质量模型
有同学去编写测试用例是“凭感觉”去写,觉得覆盖主要场景就可以了,其实可以参考ISO 25010质量模型,它是一个分层的质量模型,从软件的功能性、兼容性、安全性、可靠性、易用性、效率、可维护性、可移植性等八个方面确保软件质量。 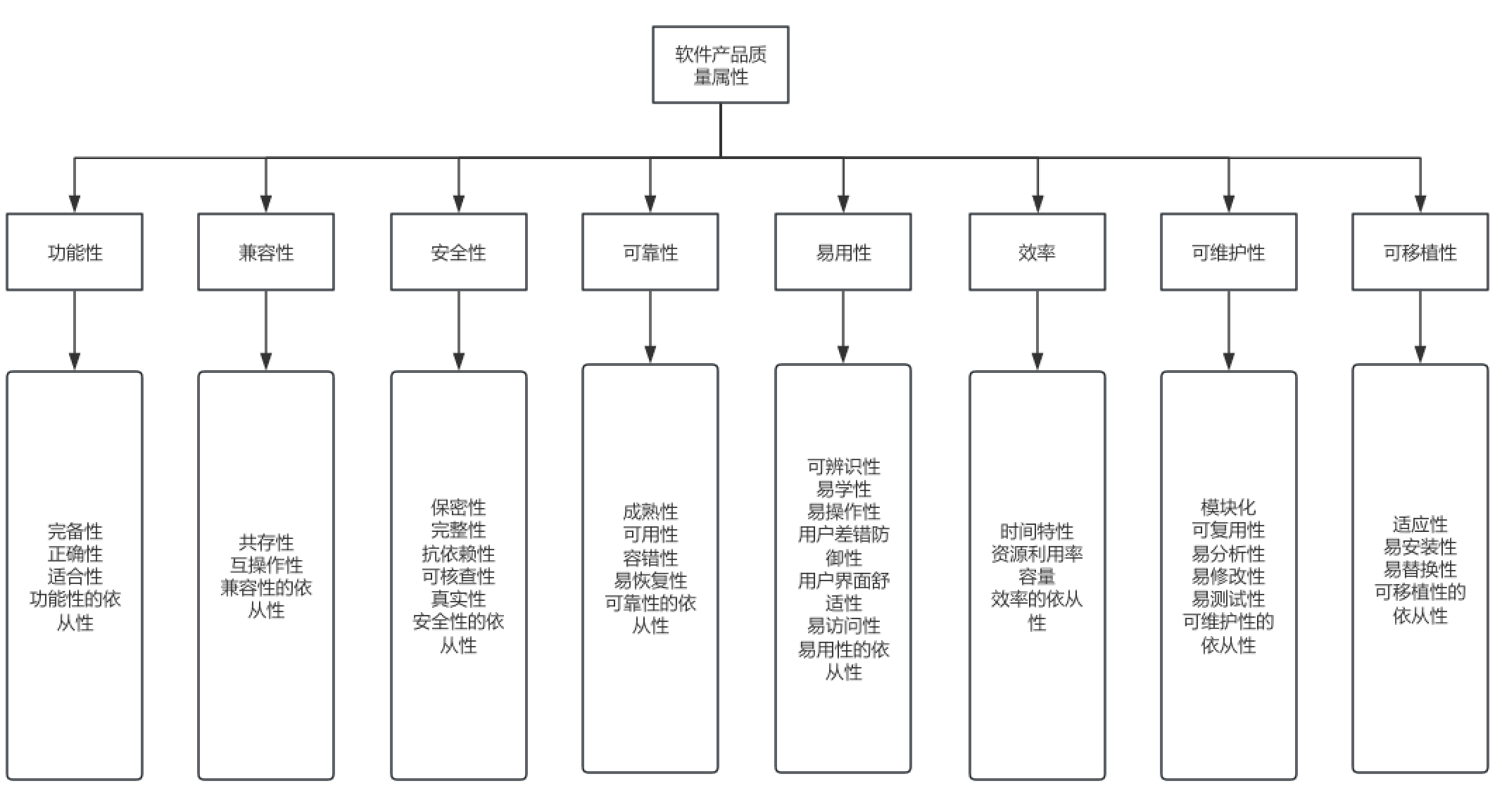
2.流程类——路径分析法
根据软件产品质量模型思考测试点,就像画一朵花,心里先有花的大概轮廓,这些轮廓就等同“测试点”  有了轮廓后需要画花朵的线条,线条就是“实际测试用例”
有了轮廓后需要画花朵的线条,线条就是“实际测试用例” 
对于流程类的,先梳理业务场景,再进行业务建模,再进行业务路径分析,最后对每个路径进行扩展,以用户登录为例进行说明
梳理业务流程
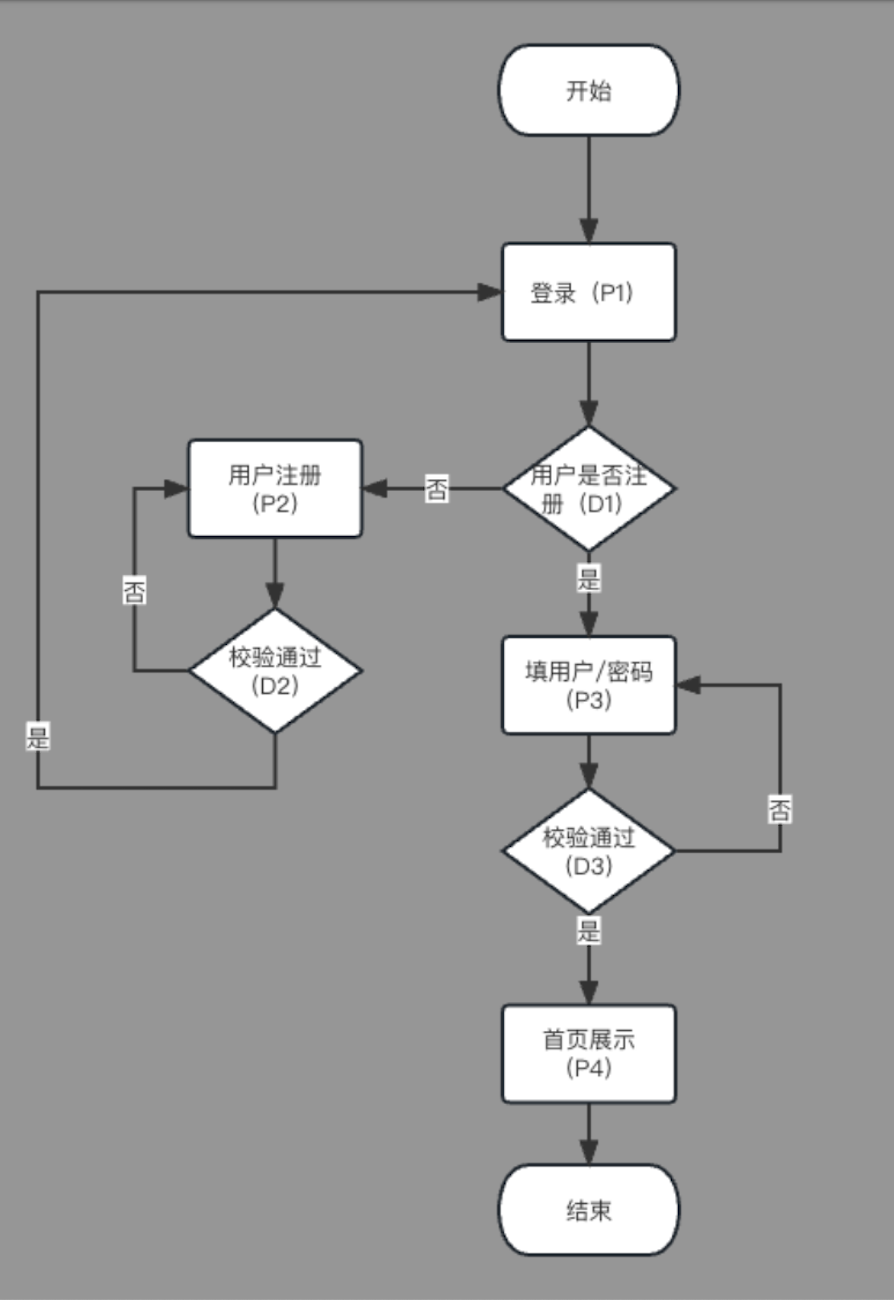
进行业务分析 罗列涉及的业务路径,并且备注场景
| 编号 | 路径 | 场景 |
|---|---|---|
| 1 | P1-D1-P3-D3-P4 | 已注册用户成功登录。 |
| 2 | P1-D1-P3-D3-P3 | 已注册用户失败登录。 |
| 3 | P1-D1-P3-D3-P3-D3-P4 | 已注册用户第二次成功登录。 |
| 4 | P1-D1-P2-D2-P2 | 注册用户失败。 |
| 5 | P1-D1-P2-D2-P1 | 注册用户成功。 |
| 6 | P1-D1-P2-D2-P1-D1-P3-D3-P3 | 注册用户成功后,登录失败。 |
| 7 | P1-D1-P2-D2-P1-D1-P3-D3-P4 | 注册用户成功后,登录成功。 |
| 8 | P1-D1-P2-D2-P1-D1-P3-D3-P3-D3-P4 | 注册用户成功后,首次失败,第二次成功。 |
| . | ... |
- 扩展用例 部分场景设计不够全面,还需要对其进行扩展,例:注册用户失败场景,情况有多种,需要对其扩展
| 编号 | 场景 | 扩展 |
|---|---|---|
| 1 | 注册用户失败(P1-D1-P2-D2-P2) | 输入密码不符合规范 |
| 2 | 前后两次输入密码不一致 | |
| 3 | 用户名已经被注册 | |
| . | ... |
3.数据类——等价类/边界值分析法
将测试效果相同的测试输入归为同一类,这种得到的分类就成为“等价类”,所以在每个等价类选中一种测试样本就行了,不需要遍历全部的值
- 有效等价类与无效等价类的划分 例如针对某参数取值范围 [-10,10],按照等价类划分为:有效等价类与无效等价类,如下:
| 有效等价类 | 无效等价类 |
|---|---|
| [-10, 10] | 小于-10 或 大于10 |
- 边界值样本 利用边界值为每个等价类选择样本数据,如下:
| 有效等价类 | 无效等价类 |
|---|---|
| -10, 0, 10 | -11, 11 |
- 中间值样本 同时还需要对有效等价类中选取一个取值中间的样本数据
| 有效等价类 | 无效等价类 |
|---|---|
| -10, -5, 0, 6, 10 | -11, 11 |
- 等价分析建模 以邮箱注册进行说明,要求6~8位字符,包含字母、数字、下划线,以字母开头,对输入数据进行等价划分
| 输入条件 | 有效等价类 | 编号 | 无效等价类 | 编号 |
|---|---|---|---|---|
| 邮箱名 | 6~8个字符 | 1 | <6位、>8位、空 | 2、3、4 |
| 包含字母、数字、下划线 | 5 | 除字母/数字/下划线的、特殊字符、非打印字符、中文字符 | 6、7、8 | |
| 以字母开头 | 9 | 以数字或下划线开头 | 10 |
同时再进行测试用例编写
| 编号 | 输入数据 | 覆盖等价类 | 预期输出 |
|---|---|---|---|
| 1 | test_123 | 1、5、9 | 成功注册 |
| 2 | test | 2、5、9 | 非法输入 |
| 3 | test_123456789_123456789 | 3、5、9 | 非法输入 |
| 4 | null | 4 | 非法输入 |
| 5 | test%%123 | 1、6、9 | 非法输入 |
| 6 | test 123 | 1、7、9 | 非法输入 |
| 7 | test哈123 | 1、8、9 | 非法输入 |
| 8 | 123_test | 1、5、10 | 非法输入 |
4.组合类——正交分析法
1.测试用例的组合 当输入的数据有多种条件组合时,那么用例组合可能会有很多。 假设需要对写邮件场景的参数进行测试,参数如下:
| 类型 | 数据 |
|---|---|
| 邮件格式 | html, Plain Text |
| 语言 | English, French, Spanish |
| 附近类型 | None, Image, Document |
如果使用全组合测试,需要测试2 x 3 x 3 = 18种组合。但通过组合正交法,可以用较少的测试用例来覆盖这些组合。
组合正交法的原理 组合正交法通过选择一个正交数组(Orthogonal Array),来设计覆盖所有参数及其取值范围的测试用例。正交数组是一种矩阵,能够保证在较少的测试用例中,尽可能多地覆盖所有参数的不同组合。正交数组中的每一行代表一个测试用例,每一列代表一个参数,每个单元格的值代表该参数的取值。
设计步骤 确定参数和取值
| 类型 | 数据 |
|---|---|
| 邮件格式 | html, Plain Text |
| 语言 | English, French, Spanish |
| 附近类型 | None, Image, Document |
使用工具设计用例 需要一个适合三个参数(邮件格式、语言、附件类型)且每个参数有不同取值的正交表。这里通过python3 按照allpairspy包,然后输入参数进行用例设计
1.from allpairspy import AllPairs
2.
3.parameters = [
4. ["html", "Plain Text"],
5. ["English", "French", "Spanish"],
6. ["None", "Image", "Document"],
7.]
8.
9.print("PAIRWISE:")
10.for i, pairs in enumerate(AllPairs(parameters)):
11. print("{:2d}: {}".format(i, pairs))
12.
13.if __name__ == '__main__':
14. pass输出
输出:
PAIRWISE:
0: ['html', 'English', 'None']
1: ['Plain Text', 'French', 'None']
2: ['Plain Text', 'Spanish', 'Image']
3: ['html', 'Spanish', 'Document']
4: ['html', 'French', 'Image']
5: ['Plain Text', 'English', 'Document']
6: ['Plain Text', 'English', 'Image']
7: ['Plain Text', 'French', 'Document']
8: ['Plain Text', 'Spanish', 'None']- 实际应用中的考虑 在实际应用中,需要根据具体情况决定是否使用组合正交法。对于一些关键功能或高风险区域,可能仍需要进行全组合测试。而对于较低风险的区域或在资源有限的情况下,组合正交法提供了一种有效的方法来最大化测试覆盖率,同时减少测试用例数量。